LIFE Star Catalog¶
Introduction¶
One of the main use cases of the LIFE Target Database is to enable the creation of the LIFE Star Catalog (LIFE-StarCat). It is the stellar sample of potential targets that is used by LIFEsim to provide mission yield estimates. In this tutorial we guide you through how the 4th version of this catalog was created. Following our example you can learn how you could create your own catalog for your science project.
Important: The newest catalog is version 5. There is no tutorial for its creation (yet) but you can access it atLIFE-StarCat5.
File location¶
Make sure to run this file in the correct location (data_generation/life_td_data_generation/catalog). The file in data_generation/docs/source/tutorials is only intended for proper display on the webpage. Alternatively you can adapt the paths to the modules and saving locations.
Getting started¶
We start by importing the required Python modules for this tutorial. Be aware that you will need to have them installed in your environment for this to work.
[1]:
import astropy as ap # Used for votables
import numpy as np # Used for arrays
import pyvo as vo # Used for catalog query
Next we import the life_td_data_generation specific functions from the modules.
[2]:
# Self created modules
from provider.utils import query
from utils.io import objecttostring
In case you don’t want to download the life_td_data_generation package you can also just use the two functions below. Be aware in that case you might need to adjust the paths for saving of the catalog and the plotting functions won’t work.
[3]:
def objecttostring(cat):
for i in cat.colnames:
if cat[i].dtype == object: # object =adaptable length string
# transform the type into string
cat[i] = cat[i].astype(str)
return cat
def query(link, query, catalogs=[], no_description=True):
"""
Performs a query via TAP on the service given in the link parameter.
If a list of tables is given in the catalogs parameter,
those are uploaded to the service beforehand.
:param str link: Service access URL.
:param str query: Query to be asked of the external database service
in ADQL.
:param catalogs: List of astropy tables to be uploaded to the
service.
:type catalogs: list(astropy.table.table.Table)
:param bool no_description: Defaults to True, wether description gets removed
:returns: Result of the query.
:rtype: astropy.table.table.Table
"""
# defining the vo service using the given link
service = vo.dal.TAPService(link)
# without upload tables
if catalogs == []:
result = service.run_sync(query.format(**locals()), maxrec=1600000)
# with upload tables
else:
tables = {}
for i in range(len(catalogs)):
tables.update({f"t{i + 1}": catalogs[i]})
result = service.run_sync(
query, uploads=tables, timeout=None, maxrec=1600000
)
cat = result.to_table()
# removing descriptions because merging of data leaves wrong description
for col in cat.colnames:
if no_description:
cat[col].description = ""
return cat
Querying the Database¶
We will now query the LIFE Target Database (life_td) for the data needed to create the catalog. We specify the distance cut as 30 parsec according to the latest LIFE catalog version (4).
[4]:
distance_cut = 30.0
Now we define the concrete query. It is one of the provided examples at http://dc.zah.uni-heidelberg.de/life/q/ex/examples and returns parameters for all objects of type star with distances smaller than 30 pc. We also give the link for the service.
[5]:
adql_query = """
SELECT o.main_id, sb.coo_ra, sb.coo_dec, sb.sptype_string,
sb.plx_value, sb.dist_st_value, sb.coo_gal_l, sb.coo_gal_b,
sb.teff_st_value, teff_source.ref AS teff_ref,
sb.mass_st_value, mass_source.ref AS mass_ref,
sb.radius_st_value, radius_source.ref AS radius_ref,
sb.binary_flag, binary_source.ref AS binary_ref,
sb.mag_i_value, sb.mag_j_value, sb.class_lum, sb.class_temp,
o_parent.main_id AS parent_main_id, sb_parent.sep_ang_value
FROM life_td.star_basic AS sb
JOIN life_td.object AS o ON sb.object_idref=o.object_id
LEFT JOIN life_td.h_link AS h ON o.object_id=h.child_object_idref
LEFT JOIN life_td.object AS o_parent ON
h.parent_object_idref=o_parent.object_id
LEFT JOIN life_td.star_basic AS sb_parent ON
o_parent.object_id=sb_parent.object_idref
LEFT JOIN life_td.source AS radius_source ON
sb.radius_st_source_idref=radius_source.source_id
LEFT JOIN life_td.source AS mass_source ON
sb.mass_st_source_idref=mass_source.source_id
LEFT JOIN life_td.source AS teff_source ON
sb.teff_st_source_idref=teff_source.source_id
LEFT JOIN life_td.source AS binary_source ON
sb.binary_source_idref=binary_source.source_id
WHERE o.type = 'st' AND sb.dist_st_value < """ + str(distance_cut)
service = "http://dc.zah.uni-heidelberg.de/tap"
# service = "http://dc.g-vo.org/tap"
Next we perform the actual query.
Note: If you use the query function through the import and it takes long (<1min) that is because that function uses the asynchroneous modus which can take longer if there are many big queries on the same server. In that case instead run the cell with the query function written out instead of imported. It uses the synchroneous modus.
[6]:
catalog = query(service, adql_query)
Let’s have a short look at what we got:
[7]:
print(catalog)
main_id coo_ra ... parent_main_id sep_ang_value
deg ... arcsec
---------------------- ------------------ ... -------------- -------------
* 61 Cyg B 316.7302660185276 ... * 61 Cyg 17.5
* 61 Cyg A 316.7247482895925 ... * 61 Cyg 17.5
BD+40 883A 315.0224464400413 ... BD+40 883 1.0
L 1578-44 B 324.1601460120721 ... L 1578-44 1.0
L 1578-44 A 324.16073469423293 ... L 1578-44 1.0
UPM J2325+4717B 351.4090302929913 ... UPM J2325+4717 --
UPM J2325+4717A 351.4091812460812 ... UPM J2325+4717 --
Ross 200B 325.0050669305063 ... Ross 200 1.2
Ross 200A 325.0044367358217 ... Ross 200 1.2
... ... ... ... ...
HD 39071 87.34407314049 ... --
LP 745-67 250.50179723021 ... --
2MASSW J1338261+414034 204.6088835976029 ... --
LEHPM 5537 347.4554103764454 ... --
HD 62848 115.83953258883004 ... --
CFBDS J030135-161418 45.396532 ... --
Wolf 1014 333.14977013473833 ... --
G 130-14 357.47429569389 ... --
LP 860-46 238.48788628228536 ... --
LP 709-43 32.51528919165918 ... --
Length = 9067 rows
We can see that we obtained a table of about 10’000 stars.
Processing the result¶
Removing non main-sequence stars¶
For the LIFE mission we are only interested in main sequence stars so in the next step we remove all other stars. We first remove those without main sequence temperature classes (e.g. white dwarfs).
[8]:
ms_tempclass = np.array(["O", "B", "A", "F", "G", "K", "M"])
cat_ms_tempclass = catalog[
np.where(np.isin(catalog["class_temp"], ms_tempclass))
]
Next we remove objects that are not main sequence in luminosity class. Note that the class_lum parameter from the LIFE Target Database assumes V if no luminosity class is given in the sptype_string parameter. This is justified as the main sequence is the longest lasting evolutionary period of a star leaving the great majority of stars in this stage. This assumption was neccessary as the estimated stellar effective temperature, mass and radius values use a relation requiring luminosity class V.
[9]:
ms_lumclass = np.array(["V"])
cat_ms_lumclass = cat_ms_tempclass[
np.where(np.isin(cat_ms_tempclass["class_lum"], ms_lumclass))
]
print(cat_ms_lumclass)
main_id coo_ra ... parent_main_id sep_ang_value
deg ... arcsec
--------------- ------------------ ... -------------- -------------
* 61 Cyg B 316.7302660185276 ... * 61 Cyg 17.5
* 61 Cyg A 316.7247482895925 ... * 61 Cyg 17.5
BD+40 883A 315.0224464400413 ... BD+40 883 1.0
L 1578-44 A 324.16073469423293 ... L 1578-44 1.0
HD 239960B 336.9991483422729 ... HD 239960 113.7
HD 239960A 336.9981564512275 ... HD 239960 113.7
HD 179958 288.02093934795624 ... BD+49 2959 196.0
HD 179957 288.01949584708956 ... BD+49 2959 196.0
Wolf 1084 310.8302599214592 ... Wolf 1084 0.1
... ... ... ... ...
LP 346-21 350.99969919854044 ... --
SIPS J1906-5828 286.60564127791 ... --
L 404-10 214.3578488896829 ... --
G 85-38 75.47167763647 ... --
HD 39071 87.34407314049 ... --
HD 62848 115.83953258883004 ... --
Wolf 1014 333.14977013473833 ... --
G 130-14 357.47429569389 ... --
LP 860-46 238.48788628228536 ... --
LP 709-43 32.51528919165918 ... --
Length = 5217 rows
Now for the final catalog we want to have stellar mass values for each object. Currently the database is not able to assign model masses to some of the spectral types. This is the case when something like M or M (3) V is given in sptype_string. This will be implemented in one of the future database releases but for now we will just remove all objects without entries in mass_st_value.
[10]:
print(
cat_ms_lumclass["main_id", "mass_st_value", "sptype_string"][
cat_ms_lumclass["mass_st_value"].mask.nonzero()[0]
]
)
cat_ms_lumclass.remove_rows(cat_ms_lumclass["mass_st_value"].mask.nonzero()[0])
main_id mass_st_value sptype_string
solMass
---------------- ------------- -------------
* zet01 UMa -- A1.5Vas
HD 61606 -- K3V
BD+16 2708 -- M3V
HD 191408 -- K2.5V
HD 21209 -- K3.5V
* 54 Psc -- K0.5V
* 54 Psc -- K0.5V
HD 6440A -- K3.5V
HD 15468 -- K4.5Vk
... ... ...
HD 27274 -- K4.5Vk:
UCAC4 563-099325 -- F
UCAC2 1564860 -- M
HD 192961 -- K5.5V
HD 170209 -- K(2)V
HD 12058 -- K4.5Vk:
HD 214749 -- K4.5Vk
HD 197396 -- K2.5V
HD 109333 -- K4.5V
CD-34 1169 -- M
Length = 88 rows
Removing higher order multiples¶
For the LIFE catalog we want single stars and wide binaries that can be approximated as single stars. For that we now split the sample into single and multiple stars:
[11]:
singles = cat_ms_lumclass[np.where(cat_ms_lumclass["binary_flag"] == "False")]
multiples = cat_ms_lumclass[np.where(cat_ms_lumclass["binary_flag"] == "True")]
print(len(singles), len(multiples))
3137 1992
Next we remove higher order multiples. That means we remove systems like shown in the nextled multiples part of the following figure: 
To do that we first remove those objects, where the parent object is a child object as well. In the example above that would be “system AB”. For that we need to get the hierarchy table from life_td.
[12]:
adql_query2 = """
SELECT o.main_id as child_main_id,o.object_id
FROM life_td.object AS o
JOIN life_td.h_link AS h on o.object_id=h.child_object_idref
"""
h_link = query(service, adql_query2)
[13]:
higher_order_multiples = np.isin(
multiples["parent_main_id"], h_link["child_main_id"]
)
multiples.remove_rows(higher_order_multiples)
Now we also remove objects that have multiple parent objects, e.g., * 9 Aur has as parent WDS J05067+5136AB, WDS J05067+5136AC and WDS J05067+5136AE given.
[14]:
multi_parent = []
grouped = multiples.group_by("main_id")
ind = grouped.groups.indices
for i in range(len(ind) - 1):
if ind[i + 1] - ind[i] != 1:
multi_parent.append(grouped["main_id"][ind[i]])
single_parent_multiples = grouped[
np.where(np.invert(np.isin(grouped["main_id"], multi_parent)))
]
print(len(single_parent_multiples))
974
Since we want to get wide binaries the next step is to have a look at the given separation values. We remove those binaries where no separation value is given.
[15]:
sep_multiples = single_parent_multiples[
np.where(single_parent_multiples["sep_ang_value"].mask == False)
].copy()
Now we transform the separation values from angular into physical. This is neccessary as we want to look at in a later step at the planetery orbit stability around the habitable zone.
[16]:
sep_multiples["sep_phys_value"] = sep_multiples[
"sep_ang_value"
] # just initiating new column with same properties
sep_multiples["sep_phys_value"].unit = ap.units.AU
for i in range(len(sep_multiples)):
sep_multiples["sep_phys_value"][i] = np.round(
sep_multiples["sep_ang_value"][i] * sep_multiples["dist_st_value"][i], 1
)
Now we only keep those binaries where both components fulfill all our requirements. Meaning the posses the parameters we need to compute the orbital stability mentioned above. Those parameters are being main sequence having the separation value given.
[17]:
grouped_multiples = sep_multiples.group_by("parent_main_id")
ind = grouped_multiples.groups.indices
result = grouped_multiples[:0].copy()
for i in range(len(ind) - 1):
l = ind[i + 1] - ind[i]
if l == 2:
result.add_row(grouped_multiples[ind[i]])
result.add_row(grouped_multiples[ind[i] + 1])
[18]:
print(len(result))
418
Wide binaries¶
Now we actually focus on the wide binaries. This means we keep only objects where <10 AU planet orbits are stable. For that we use the formula from Holman and Wiegert 1999 while assuming circular orbits and neglegt projection effects of the bianry separations. The following function computes the critical separation beyond which a planet on a S-type orbit is not stable any more.
[19]:
def crit_sep(eps, mu, a_bin):
"""
Computes critical semimajor-axis for planet orbit stability.
For binary system as described in Holman and Wiegert 1999.
:param eps: Binary orbit excentricity.
:type eps:
:param mu: mass fraction with mu=m_s/(m_p+m_s), with m_s the mass
of the star considered as perturbing binary companion and m_p
the mass of the star the planet is orbiting.
:type mu:
:param a_bin: semimajor-axis of the binary stars.
:type a_bin:
:returns: Critical separation beyond which a planet on a S-type
orbit (circumstellar) and on a P-type orbit (circumbinary) is
not stable any more.
:rtype:
"""
a_crit_s = (
0.464
- 0.38 * mu
- 0.631 * eps
+ 0.586 * mu * eps
+ 0.15 * eps**2
- 0.198 * mu * eps**2
) * a_bin
a_crit_p = (
1.6
+ 5.1 * eps
- 2.22 * eps**2
+ 4.12 * mu
- 4.27 * eps * mu
- 5.09 * mu**2
+ 4.61 * eps**2 * mu**2
) * a_bin
return a_crit_s, a_crit_p
Now we assign the critical separation to each binary component.
[20]:
result["a_crit_s"] = result[
"sep_phys_value"
] # initializing column a... like sep...
for i in range(len(result)):
m_p = result["mass_st_value"][i]
if i % 2 == 0:
m_s = result["mass_st_value"][i + 1]
else:
m_s = result["mass_st_value"][i - 1]
mu = m_s / (m_p + m_s)
result["a_crit_s"][i] = crit_sep(0, mu, result["sep_phys_value"][i])[0]
# assumed circular orbit and sep_phys = a_bin
Next we keep only those where orbits up to 10AU are stable.
[21]:
final = result[:0].copy()
# wait, didn't I already define this? -> was before removing some
ind = result.group_by("parent_main_id").groups.indices
a_max = 10.0
for i in range(len(ind) - 1):
if a_max < min(result["a_crit_s"][ind[i]], result["a_crit_s"][ind[i] + 1]):
final.add_row(result[ind[i]])
final.add_row(result[ind[i] + 1])
[22]:
print(len(final))
374
Finally we combine the singles stars and wide binaries back into a single sample.
[23]:
StarCat4 = ap.table.vstack([singles, final])
Adding architecture parameter¶
For mission design trade space we are interested in the ability to take subsamples of the stars depending on ecliptic angle. We therefore add another parameter indicating if the given star is within 45 degrees from the ecliptic plane.
[24]:
def ecliptic(ang, ra, dec):
"""
Computes if position is within angle from the ecliptic.
Flag any object whose declination is contained within the region
between -(23.4+angle)*sin(RA) and +(23.4+angle)*sin(RA) with the
object's RA in degrees.
:param ang: Angle in degrees.
:type ang:
:param ra: Right ascention in degrees.
:type ra: np.array
:param dec: Array of declination in degrees.
:type dec: np.array
:returns: Flags.
:rtype: np.array
"""
ecliptic = (23.4) * np.sin(2 * np.pi * ra / 360)
flag = [
"True"
if dec[j] > -ang + ecliptic[j] and dec[j] < ang + ecliptic[j]
else "False"
for j in range(len(ra))
]
return flag
StarCat4["ecliptic_pm45deg"] = ecliptic(
45, StarCat4["coo_ra"], StarCat4["coo_dec"]
)
Let’s have a last look at our final catalog and then save the table.
[25]:
print(StarCat4)
main_id coo_ra ... ecliptic_pm45deg
deg ...
----------------------- ------------------ ... ----------------
BD-12 662 52.33246607947125 ... True
LP 1032-116 335.4571804690921 ... True
G 138-37 247.89607291868327 ... True
G 144-64 316.8518218343254 ... True
G 141-10 276.60248715442 ... True
CD-22 13916 291.14264684284916 ... True
LP 759-6 329.30281861144 ... True
SIPS J2049-1944 312.3322935777066 ... True
PM J11523+1640 178.08549480447 ... True
... ... ... ...
BD-20 6558 348.56928489779494 ... True
BD-20 6558B 348.56858731544924 ... True
LP 704-14 359.33066256794 ... True
LP 704-15 359.33575040549 ... True
G 242-44 359.46796458627824 ... False
G 242-45 359.5066840224466 ... False
2MASS J16334908-6808480 248.45438018371166 ... False
2MASS J16334976-6808488 248.45740935813626 ... False
Wolf 1561 A 334.32905356941666 ... True
Wolf 1561 B 334.3279097421108 ... True
Length = 3511 rows
This next line is to convert data from object into string type. I use object as default because it prevents data getting truncated. Though it does have issues with the astropy ecsv format.
[26]:
StarCat4 = objecttostring(StarCat4)
[27]:
StarCat4.write(
"../../../additional_data/catalogs/StarCat4.ecsv",
delimiter=",",
overwrite=True,
)
We can also look at the distance and spectral type distribution to make sure it looks reasonable.
[28]:
from utils.analysis.finalplot import starcat_distribution_plot
starcat_distribution_plot(
[StarCat4["class_temp", "dist_st_value"]],
["StarCat4"],
path="../../../plots/final_plot.png",
)
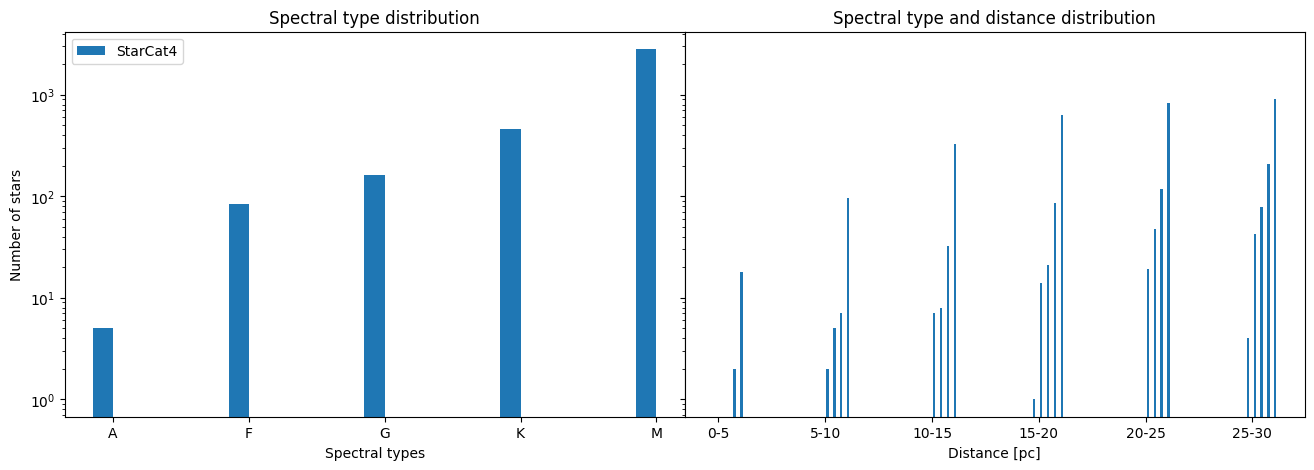
We can observe that the spectral type distribution looks as expected meaning the lower the mass of the star the more of them are within 30pc. We also see that within 20 pc we only have M and K stars in our sample. Also the spectral type distribution of the stars in our catalog between 20-25pc are nearly identical to the ones between 25-30pc. We would expect there to be way more lower mass stars in the further away distance bin. This let’s us conclude that at the end of the distance cut our catalog is magnitude limited meaning we miss quite a bit of the faint stars.
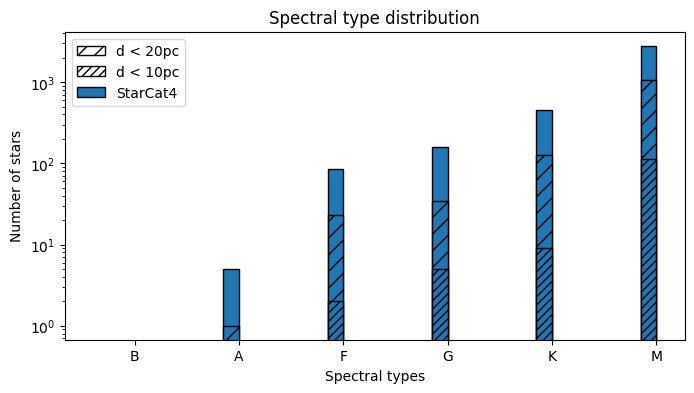
To have a look at the data using the same plot as in the RNAAS article use the code below.
[29]:
from utils.analysis.catalog_comparison_plot import (
spectral_type_histogram_catalog_comparison,
)
spectral_type_histogram_catalog_comparison(
[StarCat4["class_temp", "dist_st_value"]],
["StarCat4"],
distance_colname="dist_st_value",
spectral_type_colname="class_temp",
path="../../../plots/sthcc.png",
)
[ ]: